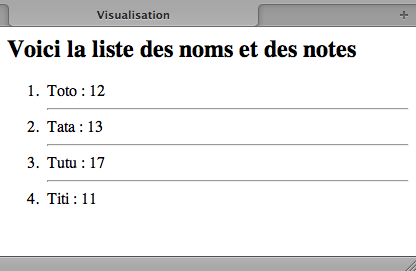
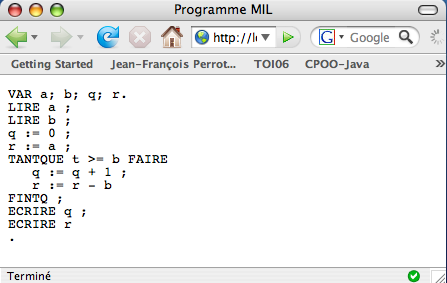
Visualisation d'un fichier de noms et de notes dans un navigateur :
à partir du fichier XML [Nom_note_2.xml]
:
<?xml version="1.0" ?>
<liste>
<eleve>
<nom> Toto</nom> <note> 12
</note>
</eleve>
<eleve>
<nom> Tata</nom> <note> 13
</note>
</eleve>
<eleve>
<nom> Tutu</nom> <note> 17
</note>
</eleve>
<eleve>
<nom> Titi</nom> <note> 11
</note>
</eleve>
</liste>on veut obtenir ce spectacle :
Pour cela, il faut transformer l'arbre XML en un texte HTML interprétable par le navigateur :
<html>
<head>
<meta http-equiv="Content-Type"
content="text/html;
charset=utf-8">
<title>Visualisation</title>
</head>
<body>
<h2> Voici le tableau des
noms et des
notes</h2>
<table border="2"
bgcolor="yellow">
<tr>
<th>Nom</th>
<th>Note</th>
</tr>
<tr>
<td>
Toto</td>
<td> 12 </td>
</tr>
<tr>
<td>
Tata</td>
<td> 13 </td>
</tr>
<tr>
<td>
Tutu</td>
<td> 17 </td>
</tr>
<tr>
<td>
Titi</td>
<td> 11 </td>
</tr>
</table>
</body>
</html>C'est l'objet de la feuille de style XSLT que voici [table.xsl]:
<?xml
version='1.0'?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version='1.0'>
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html><head><title>Visualisation</title></head>
<body>
<h2> Voici le tableau des noms et
des
notes</h2>
<table border="2"
bgcolor="yellow">
<tr>
<th>Nom</th>
<th>Note</th>
</tr>
<xsl:apply-templates/>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="liste/eleve">
<tr>
<td><xsl:value-of
select="nom"/></td>
<td><xsl:value-of
select="note"/></td>
</tr>
</xsl:template>
</xsl:stylesheet> Commentaire
La feuille de style est elle-même un fichier XML, qui fait appel à l'espace de noms"http://www.w3.org/1999/XSL/Transform".
- Les balises qui relèvent de cet espace de noms
(préfixées par "xsl:") sont interprétées
par le processeur XSLT. - Les autres (<html>
etc) sont considérées comme du texte et envoyées directement en sortie.
Les éléments <xsl:template> représentent des règles,
dont l'application à un fichier XML a pour effet d'engendrer le texte en sortie.
Leur attribut "match" détermine leur domaine d'application.
La première s'applique au document XML tout entier (symbolisé par "/").
Elle a pour effet
- de mettre en place la structure HTML
(en-tête <html><head><body> et sa fermeture </body></html>)
- d'installer le cadre de la table à engendrer
(<table> et sa fermeture, et la ligne de titres <tr><th>) - de lancer la génération des lignes successives par <xsl:apply-templates/>.
- Noter que les lignes successives sont produites après
les balises HTML ouvrantes
et avant les fermantes : elles sont insérées à leur place par un mécanisme récursif.
Pour chacun d'entre eux, elle engendre une ligne <tr> composée de deux celleules <td>
contenant la "valeur" des éléments-fils <nom> et <note> respectivement.
Première variation : attributs
Pour obtenir le même résultat à partir d'un fichier XML où les noms et les notessont représentés par des attributs et non par les éléments-fils (cf. la discussion dans le Cours n° 1),
comme ceci [Nom_note_1.xml]:
<?xml version="1.0" ?>
<liste>
<eleve nom="Toto" note="12"/>
<eleve nom="Tata" note="13"/>
<eleve nom="Tutu" note="17"/>
<eleve nom="Tutu" note="11"/>
</liste>
il suffit de modifier la seconde règle ainsi [tableAt.xsl]:
<xsl:template match="liste/eleve">
<tr>
<td><xsl:value-of select="@nom"/></td>
<td><xsl:value-of select="@note"/></td>
</tr>
</xsl:template>
La présence de l'arrobas dans select="@nom" et dans select="@note"
indique qu'on s'intéresse aux attributs de l'élément considéré et non pas à ses enfants.
Notons que <xsl:value-of> renvoie
- pour un attribut, sa valeur (cas présent)
- pour un élément, son contenu textuel (cas précédent).
Deuxième variation : liste
On veut maintenant afficher ceci, à partir de notre premier fichier XML.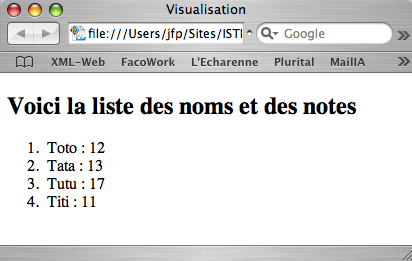
En raisonnant par analogie, on voit que la feuille de style suivante devrait faire l'affaire [list.xsl] :
<?xml
version='1.0'?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version='1.0'>
<xsl:template match="/">
<html><head><title>Visualisation</title></head>
<body>
<h2> Voici la liste des noms et des notes</h2>
<ol>
<xsl:apply-templates/>
</ol>
</body>
</html>
</xsl:template>
<xsl:template match="liste/eleve">
<li>
<xsl:value-of
select="nom"/> :
<xsl:value-of
select="note"/>
</li>
</xsl:template>
</xsl:stylesheet>Troisième variation : attributs + liste
Vous en savez assez pour rédiger une feuille de style propre à afficher en mode liste le fichier Nom_note_1.xml,et, toujours par analogie, pour en rédiger deux autre pour afficher le fichier ex.xml :
<?xml version="1.0"?>en mode table et en mode liste.
<liste>
<eleve nom='Pierre'> <note> 12 </note>
</eleve>
<eleve nom="Paul"> <note> 13 </note>
</eleve>
<eleve nom='Jacques'> <note>17 </note>
</eleve>
</liste>