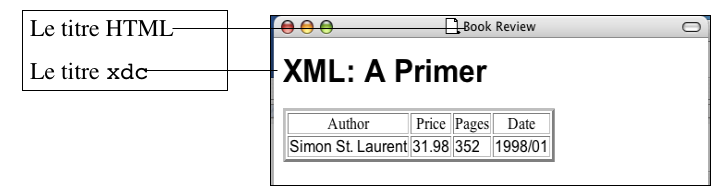
Souvent utilisée pour exprimer la structure d'une entité quelconque.
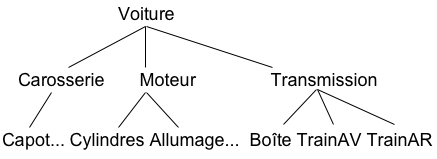
Les machines savent parfaitement traiter des arbres
mais les hommes ont besoin de représenter les mêmes arbres par des textes (très longues chaînes de caractères).
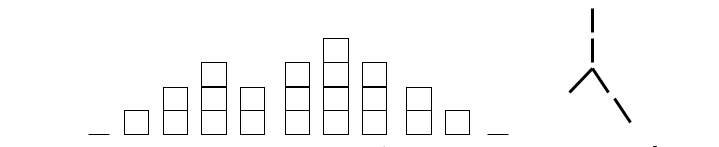
Les arbres sont des structures à deux dimensions (la descendance parent-enfant [verticale] et l'ordre entre les enfants [horizontale]).
Les chaînes de caractères sont des structures à une seule dimension.
Il faut donc coder les arbres sous forme de chaînes de caractères.
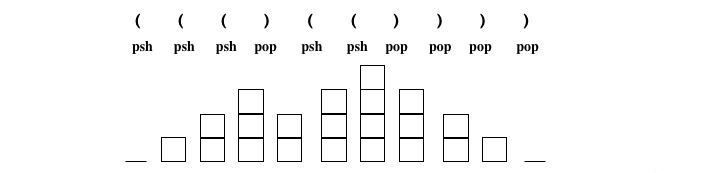
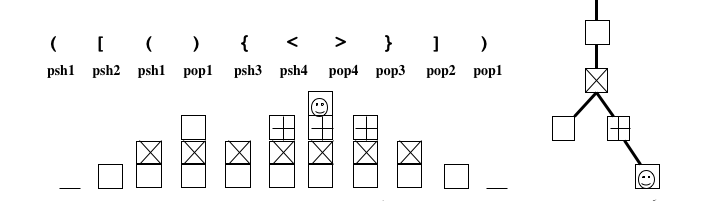
Un des moyens pour effecuer ce codage est fourni par les systèmes de parenthèses.
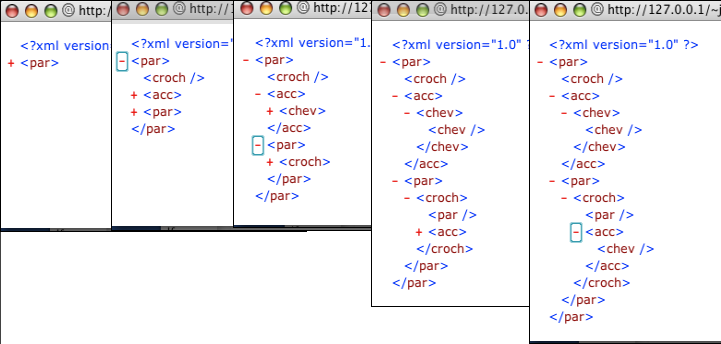
Le principe de XML n'est pas autre chose qu'une généralisation des systèmes de parenthèses.